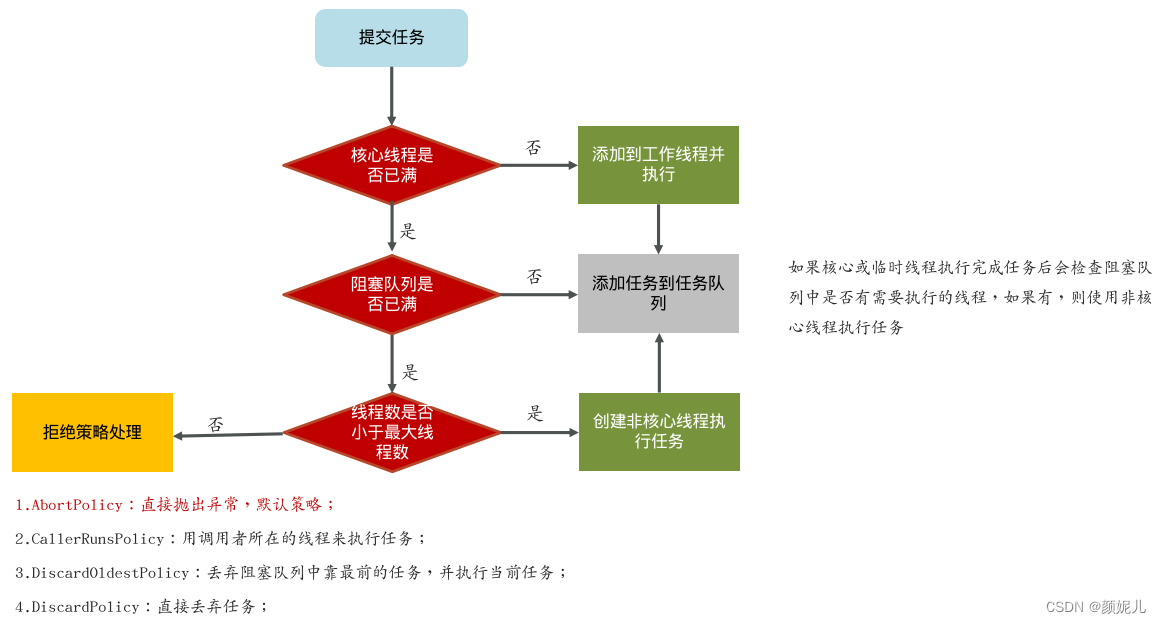
线程池的核心参数(原理)
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize 核心线程数目
- maximumPoolSize 最大线程数目 = (核心线程+救急线程的最大数目)
- keepAliveTime 生存时间 : 救急线程的生存时间,生存时间内没有新任务,此线程资源会释放
- unit 时间单位 :救急线程的生存时间单位,如秒、毫秒等
- workQueue :当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务
- threadFactory 线程工厂 :可以定制线程对象的创建,例如设置线程名字、是否是守护线程等
- handler 拒绝策略:当所有线程都在繁忙,workQueue 也放满时,会触发拒绝策略
使用Demo:
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class ThreadPoolDemo implements Runnable {
public static void main(String[] args) {
//创建阻塞队列
LinkedBlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(100);
ArrayBlockingQueue<Runnable> arrayBlockingQueue = new ArrayBlockingQueue<>(5);
//创建工厂
ThreadFactory threadFactory = new ThreadFactory() {
AtomicInteger atomicInteger = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
//创建线程把任务传递进去
Thread thread = new Thread(r);
//设置线程名称
thread.setName("MyThread: "+atomicInteger.getAndIncrement());
return thread;
}
};
ThreadPoolExecutor pool = new ThreadPoolExecutor(
2,
5,
1,
TimeUnit.SECONDS,
arrayBlockingQueue,
threadFactory,
new ThreadPoolExecutor.DiscardOldestPolicy());
for (int i = 0; i < 100; i++) {
pool.submit(new ThreadPoolDemo());
}
pool.shutdown();
}
@Override
public void run() {
//执行业务
System.out.println(Thread.currentThread().getName()+" 进来了");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"出去了");
}
}
线程池中常见的阻塞队列
workQueue:当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务。
- ArrayBlockingQueue:基于数组结构的有界阻塞队列,FIFO。
- LinkedBlockingQueue:基于链表结构的有界阻塞队列,FIFO。
- DelayedWorkQueue :是一个优先级队列,它可以保证每次出队的任务都是当前队列中执行时间最靠前的
- SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作。
ArrayBlockingQueue的LinkedBlockingQueue区别: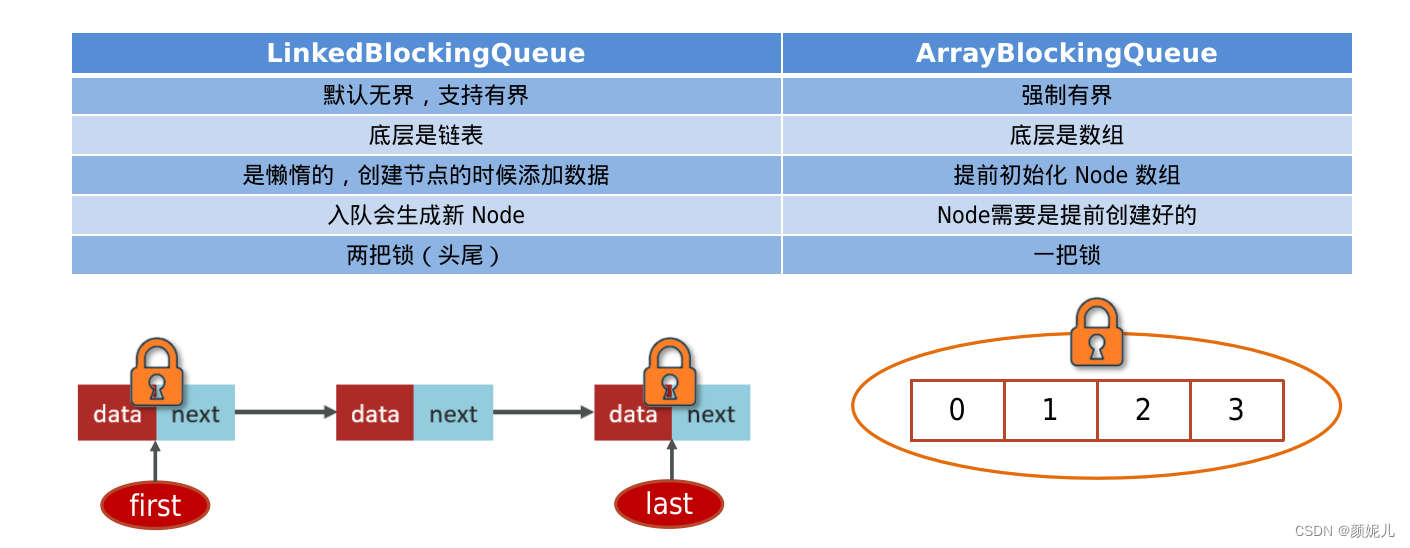
确定核心线程数
- IO密集型任务:核心线程数大小设置为2N+1(N为当前CPU的核数)
- 一般来说:文件读写、DB读写、网络请求等
- CPU密集型任务:核心线程数大小设置为N+1
- 一般来说:计算型代码、Bitmap转换、Gson转换等
查看机器的CPU核数:
public static void main(String[] args) {
//查看机器的CPU核数
System.out.println(Runtime.getRuntime().availableProcessors());
}
参考回答:
- 高并发、任务执行时间短 :( CPU核数+1 ),减少线程上下文的切换
- 并发不高、任务执行时间长
- IO密集型的任务 : (CPU核数 * 2 + 1)
- 计算密集型任务 :( CPU核数+1 )
- 并发高、业务执行时间长,解决这种类型任务的关键不在于线程池而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,增加服务器是第二步,至于线程池的设置,设置参考上一条
线程池的种类
在java.util.concurrent.Executors类中提供了大量创建连接池的静态方法,以下四种比较常见。
1. 创建使用固定线程数的线程池 ——适用于任务量已知,相对耗时的任务
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
核心线程数与最大线程数一样,没有救急线程
阻塞队列是LinkedBlockingQueue,最大容量为Integer.MAX_VALUE
举例:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class FixedThreadPoolCase {
static class FixedThreadDemo implements Runnable{
@Override
public void run() {
String name = Thread.currentThread().getName();
for (int i = 0; i < 2; i++) {
System.out.println(name + ":" + i);
}
}
}
public static void main(String[] args) throws InterruptedException {
//创建一个固定大小的线程池,核心线程数和最大线程数都是3
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 5; i++) {
executorService.submit(new FixedThreadDemo());
Thread.sleep(10);
}
executorService.shutdown();
}
}
运行结果:
pool-1-thread-1:0
pool-1-thread-1:1
pool-1-thread-2:0
pool-1-thread-2:1
pool-1-thread-3:0
pool-1-thread-3:1
pool-1-thread-1:0
pool-1-thread-1:1
pool-1-thread-2:0
pool-1-thread-2:1
2. 单线程化的线程池,它只会用唯一的工作线程来执行任 务,保证所有任务按照指定顺序(FIFO)执行——适用于按照顺序执行的任务
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
核心线程数和最大线程数都是1
阻塞队列是LinkedBlockingQueue,最大容量为Integer.MAX_VALUE
举例:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class NewSingleThreadCase {
static int count = 0;
static class Demo implements Runnable {
@Override
public void run() {
count++;
System.out.println(Thread.currentThread().getName() + ":" + count);
}
}
public static void main(String[] args) throws InterruptedException {
//单个线程池,核心线程数和最大线程数都是1
ExecutorService exec = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
exec.execute(new Demo());
Thread.sleep(5);
}
exec.shutdown();
}
}
运行结果:
pool-1-thread-1:1
pool-1-thread-1:2
pool-1-thread-1:3
pool-1-thread-1:4
pool-1-thread-1:5
pool-1-thread-1:6
pool-1-thread-1:7
pool-1-thread-1:8
pool-1-thread-1:9
pool-1-thread-1:10
3. 可缓存线程池——适合任务数比较密集,但每个任务执行时间较短的情况
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
核心线程数为0
最大线程数是Integer.MAX_VALUE
阻塞队列为SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作。
举例:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class CachedThreadPoolCase {
static class Demo implements Runnable {
@Override
public void run() {
String name = Thread.currentThread().getName();
try {
//修改睡眠时间,模拟线程执行需要花费的时间
Thread.sleep(100);
System.out.println(name + "执行完了");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
//创建一个缓存的线程,没有核心线程数,最大线程数为Integer.MAX_VALUE
ExecutorService exec = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
exec.execute(new Demo());
Thread.sleep(1);
}
exec.shutdown();
}
}
运行结果:
pool-1-thread-1执行完了
pool-1-thread-2执行完了
pool-1-thread-3执行完了
pool-1-thread-4执行完了
pool-1-thread-5执行完了
pool-1-thread-6执行完了
pool-1-thread-7执行完了
pool-1-thread-8执行完了
pool-1-thread-9执行完了
pool-1-thread-10执行完了
4. 提供了“延迟”和“周期执行”功能的ThreadPoolExecutor。
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), handler);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue(), threadFactory, handler);
}
举例
import java.util.Date;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ScheduledThreadPoolCase {
static class Task implements Runnable {
@Override
public void run() {
try {
String name = Thread.currentThread().getName();
System.out.println(name + ", 开始:" + new Date());
Thread.sleep(1000);
System.out.println(name + ", 结束:" + new Date());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
//按照周期执行的线程池,核心线程数为2,最大线程数为Integer.MAX_VALUE
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(2);
System.out.println("程序开始:" + new Date());
/**
* schedule 提交任务到线程池中
* 第一个参数:提交的任务
* 第二个参数:任务执行的延迟时间
* 第三个参数:时间单位
*/
scheduledThreadPool.schedule(new Task(), 0, TimeUnit.SECONDS);
scheduledThreadPool.schedule(new Task(), 1, TimeUnit.SECONDS);
scheduledThreadPool.schedule(new Task(), 5, TimeUnit.SECONDS);
Thread.sleep(5000);
// 关闭线程池
scheduledThreadPool.shutdown();
}
}
运行结果:
程序开始:Mon Apr 29 22:26:18 CST 2024
pool-1-thread-1, 开始:Mon Apr 29 22:26:18 CST 2024
pool-1-thread-2, 开始:Mon Apr 29 22:26:19 CST 2024
pool-1-thread-1, 结束:Mon Apr 29 22:26:19 CST 2024
pool-1-thread-2, 结束:Mon Apr 29 22:26:20 CST 2024
pool-1-thread-1, 开始:Mon Apr 29 22:26:23 CST 2024
pool-1-thread-1, 结束:Mon Apr 29 22:26:24 CST 2024
综上:
newFixedThreadPool:创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待
newSingleThreadExecutor:创建一个单线程化的线程池,它只会用唯一的工作线程来执行任 务,保证所有任务按照指定顺序(FIFO)执行
newCachedThreadPool:创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程
newScheduledThreadPool:可以执行延迟任务的线程池,支持定时及周期性任务执行
为什么不使用Excutors创建线程池
参考阿里开发手册《Java开发手册-嵩山版》

ps:OOM是指内存溢出。
最后,建议根据计算机的条件使用ThreadPoolExecutor创建线程池(突然感觉上一节白学了,唉~)。










![[iOS]组件化开发](https://img-blog.csdnimg.cn/direct/f37a3b1d57174d01ae104218fa1b11d3.png)
